
 科技让生活更美好
科技让生活更美好
冯提莫 病变

新智元报道。
编辑:艾伦好困
【新智元简介】新款SOTA再次亮相,Code Llama系列最强车型发布。70B代码模型一举击败GPT-4,开源代码登陆各大平台,大佬们直接玩了起来。
今天,Meta正式发布了Code Llama 70B,作为Code Llama系列中最大和最强大的版本,它一举击败了GPT-4!
目前,该模型有三个版本,均可免费用于研究和商业目的:
CodeLlama – 70B:基础代码模型; CodeLlama – 70B – Python:专门针对Python的 70B模型; CodeLlama – 70B – Instruct:专门用于理解自然语言指令的模型。
随着8月发布的代码Llama 7B、13B和34B,这个家已经完成。
 htc发布新机
htc发布新机
地址:https://ai . meta . com/research/publications/code-llama-open-foundation-models-for-code/
事实上,Code Llama在发布时已经展示了其良好的实力,并且在多个代码生成模型中处于领先地位。
然而,GPT-4仍然以67.0的人类评价分数(pass@1)遥遥领先(代号Llama 34B为53.7)。
虽然后来Code Llama的微调版本取得了更好的效果,但它并没有进入这种官方形式的Meta。
但是!在寒窗苦读五个月后,Code Llama终于一鸣惊人,并以最强的70B型号在所有三项测试中名列前茅。

其中,CodeLlama-70B-Instruct在HumanEval上直接获得了67.8的高分,在目前最强的开源模型中名列前茅。
可以说,除了GPT-4,其他类似型号几乎不可能与之匹敌。

对此,LeCun转发并宣传了自己的新模型:“新一代Code Llama仍然是开源的,就像它的前辈一样。」

最后发现我的AI是个小宝,还加大了宣传力度:

我们正式开源了一个全新且更加强大的Code Llama,包含一个庞大的700亿参数的模型。 在当今的AI域,编写和编辑代码已经成为了最关键的应用之一。同样,能够编程也对AI模型在其他领域进行更加严密和逻辑性的信息处理显得尤为重要。 我对我们在这方面取得的进展感到非常自豪,并且非常期待在未来的Llama 3及后续模型中加入这些先进的成果。
技术细节
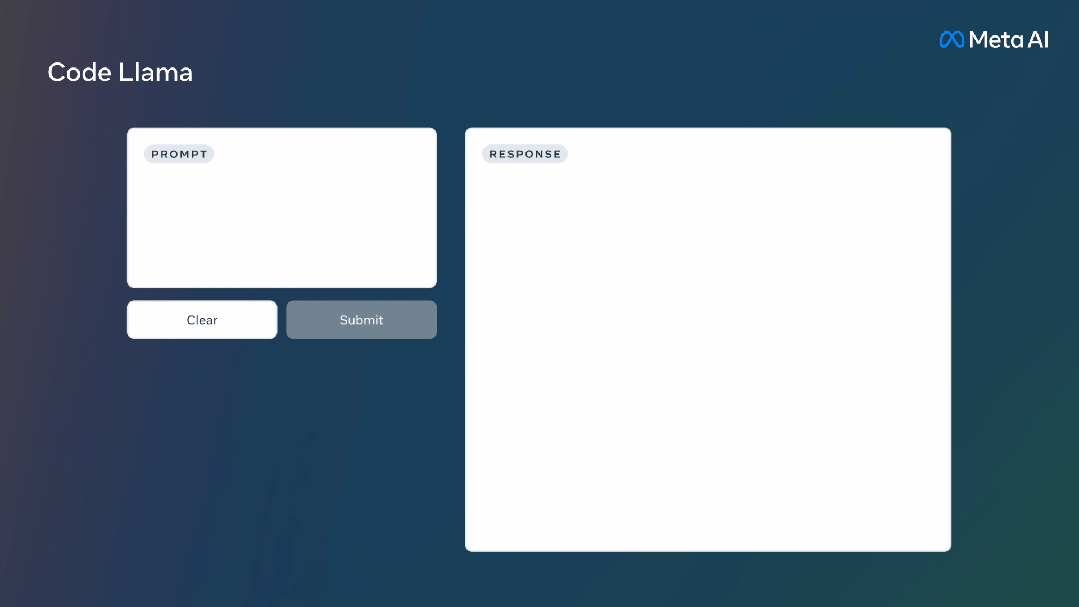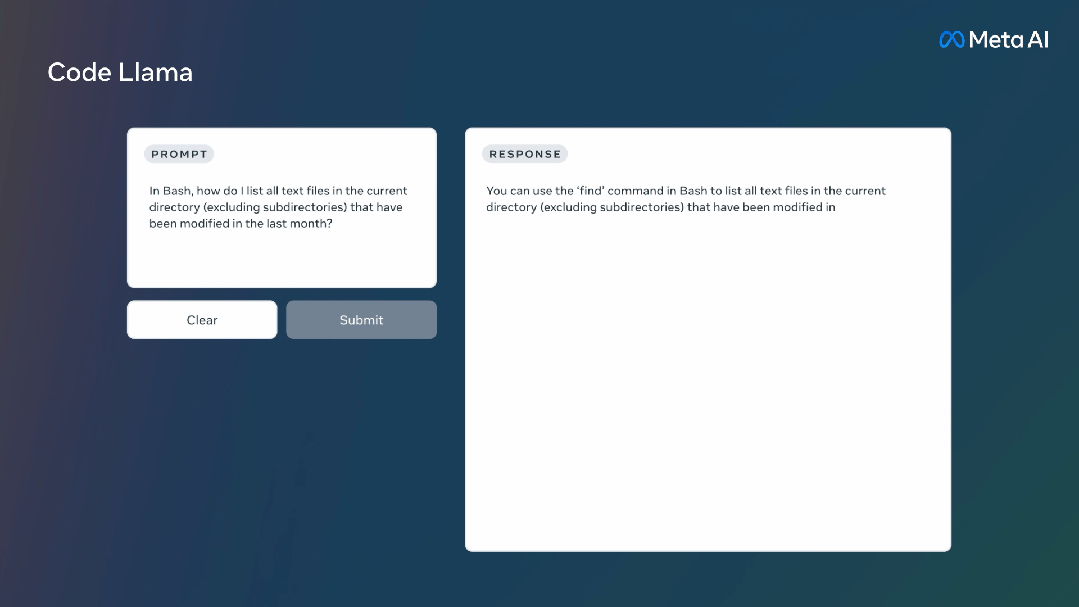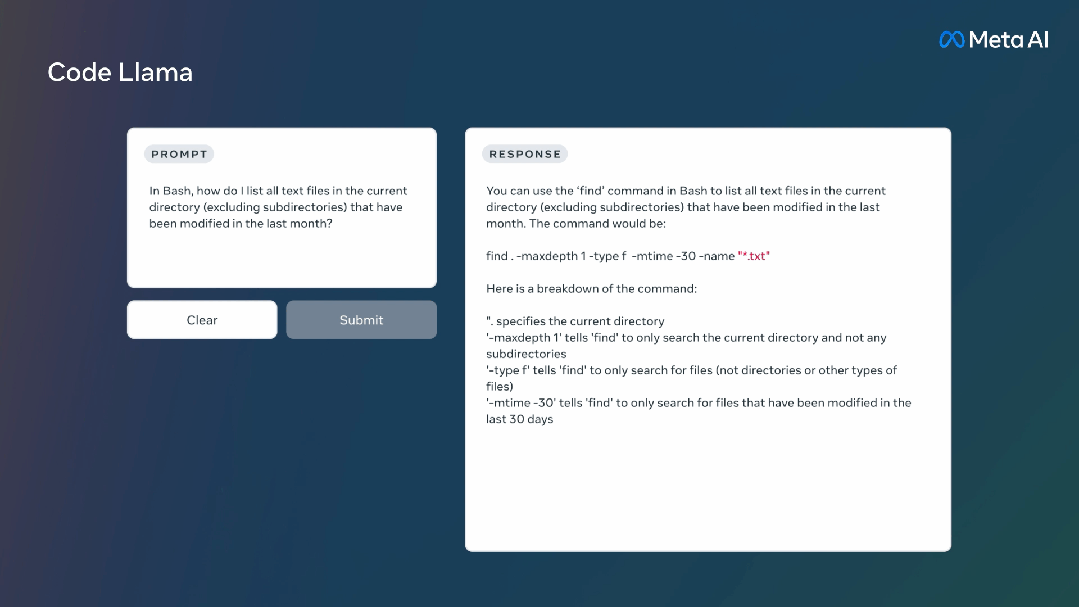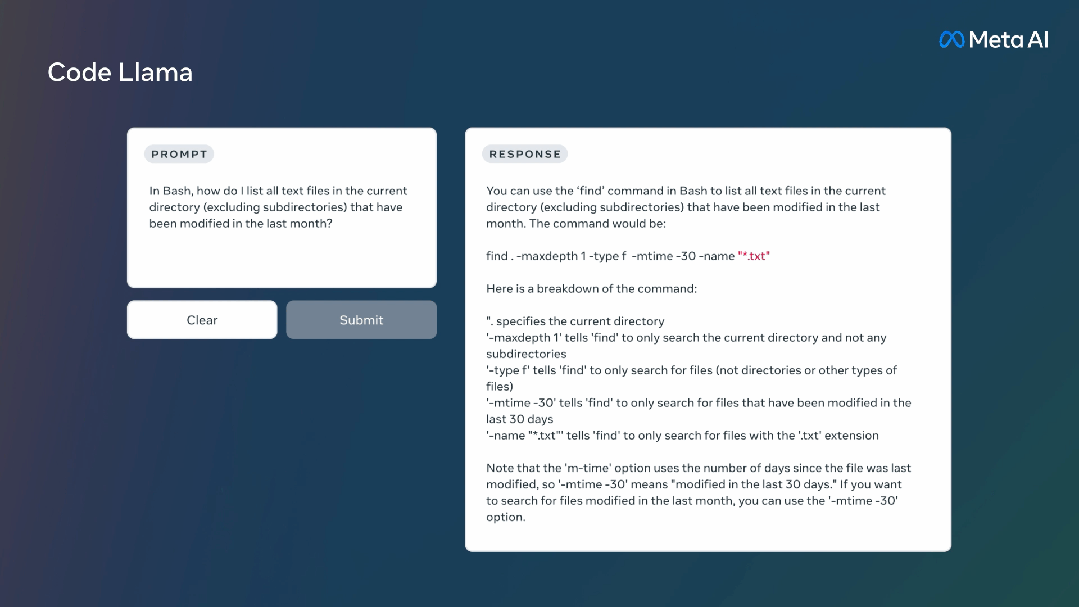
Code Llama是一个大型语言模型,可以通过文本提示生成代码。它不仅可以提高现有开发人员的工作效率,还可以降低新手程序员的学习门槛。
Meta希望将Code Llama打造为一款不仅可以提高生产力,还具有教育价值的工具,并帮助程序员创建更稳定、文档更完善的软件。
Code Llama是基于Llama 2开发的版本,专门用于编程任务。
通过在专门为编码设计的数据集上进行深度训练,Code Llama可以理解并生成代码,并帮助完成编程任务(如编写函数、代码完成和调试)。
它还支持许多流行的编程语言,包括Python、C++、Java、PHP、Typescript(Javascript)、C#和Bash。
到目前为止,Code Llama系列已经收集了四个音阶,参数分别为7B,13B,34B和70B。
前三个模型使用500B token代码和相关数据进行训练,而新发布的70B模型使用1TB token。
此外,7B和13B的基本模型和指令模型已经通过中间填充(FIM)函数进行了训练,它们具有将新代码直接插入现有代码的能力(代码补全)。
Code Llama系列型号针对不同要求和性能要求进行了优化:
7B模型可以在单个GPU上运行,适用于快速响应场景。型号34B和70B提供更高级的编码辅助功能,但运行速度较慢。
Code Llama可以处理长达100000 token的上下文,这意味着模型可以理解并生成更长的程序代码。
这对于在大型代码库中调试任务特别有用,开发人员可以提供大量代码上下文来获得更准确的编码建议。

此外,Code Llama还推出了两个特殊版本:Code Llama-Python和Code Llama-Instruct。
考虑到Python在AI社区中的重要性,Code Llama-Python专门针对Python代码进行了优化(使用100B token的Python代码数据进行微调),以使其在生成Python代码时更加流畅和准确。
CodeLlama-70B-Python还可以处理一系列任务,例如web爬行、数据分析、机器学习(ML)和Web开发。

Code Llama-Instruct通过接受自然语言指令和预期输出进行训练,这使其更擅长根据用户的需求生成代码或答案。
CodeLlama-70B-Instruct还可以用于处理排序、搜索、过滤和操作数据,以及实现算法(二分搜索法、斐波那契和阶乘等)。).
建议在需要生成代码时优先使用Code Llama-Instruct,以获得更安全、更有用的结果。
需要注意的是,主要用于编程问题的Code Llama和Code Llama-Python并不适合一般的自然语言任务。

基准测试
让我们看看新代码Llama在类似车型中的表现如何。这里采用了业内广泛使用的编程基准:
人类评估和最基本的Python编程(MBPP)。
HumanEval是一个包含164个编程问题的基准数据集,用于测试代码生成模型的功能正确性和逻辑,而MBPP则测试根据特定描述对模型进行编码的技能。
我们可以看到,上一代34B的性能非常出色,而参数增加了一倍的Code Llama 70B直接占据了榜单的主导地位,其性能与34B相比有了显著的提高。
其中,CodeLlama-70B-Instruct在HumanEval上的得分高达67.8分,超过了CodeGen-16 B- Mono(29.3分)和star coder(40.1分)等开放模型之前的最佳得分,并与GPT-4(68.2分)和Gemini Pro(69.4分)等闭源模型相当。
当然,为了更负责任地开发AI模型,Meta采取了多项安全措施,并对生成恶意代码的风险进行了量化评估。
结果表明,与chat GPT(GPT 3.5 Turbo)相比,Code Llama给出的答案更安全。
挑战GPT-4,编码模型被卷起!
目前,Code Llama 70B可以通过各种主流平台和框架访问和使用,例如Hugging Face、PyTorch、TensorFlow和Jupyter Notebook。
此外,Meta AI还提供了针对不同目的和语言使用和微调模型的文档和教程。

随着模型的发布,各大AI平台也加入了对Code Llama 70B的支持:


你也可以直接玩:
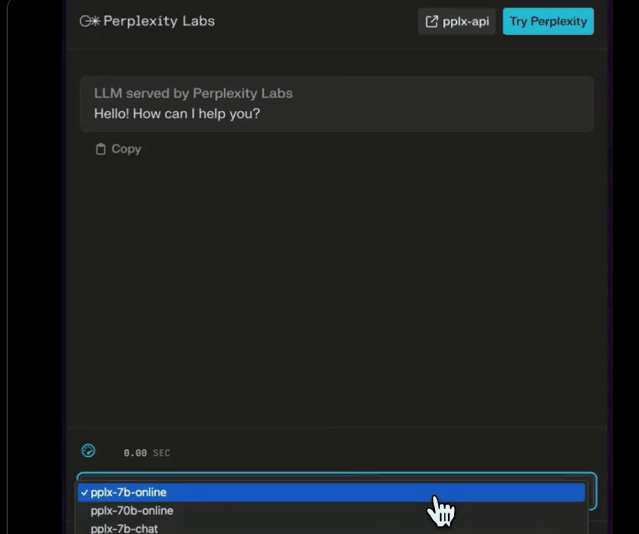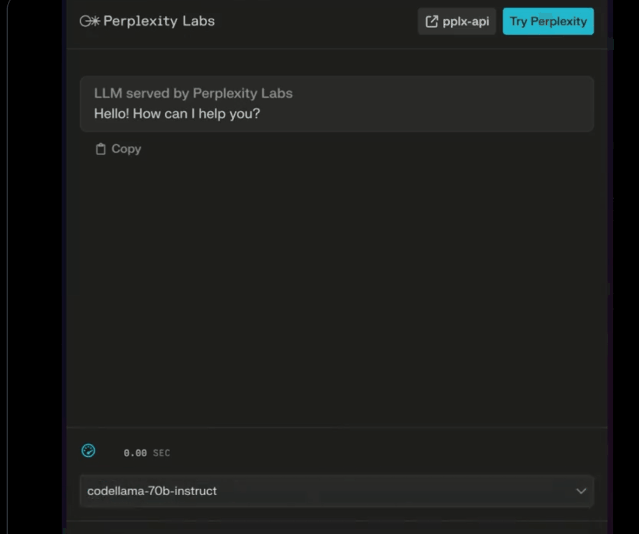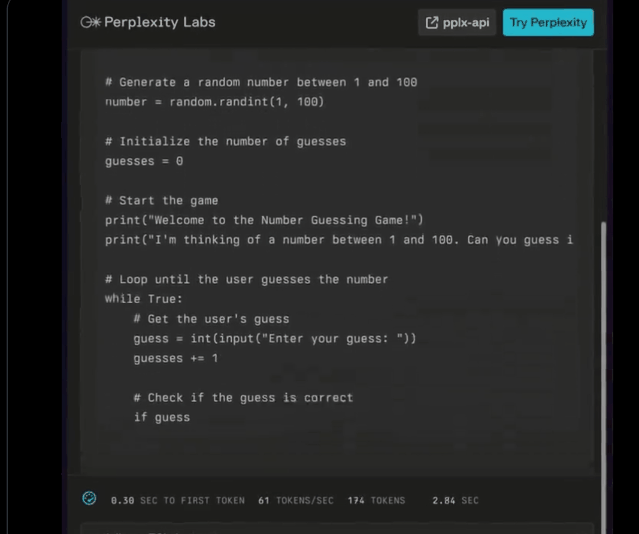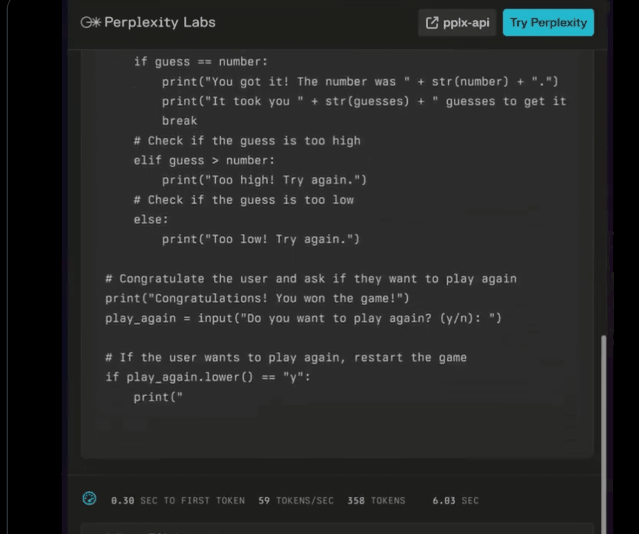
一些老板甚至将代码Llama 70B运行到苹果的处理器上,但它“有点热”。

然后这个简单地将编码Llama 70B直接量化为4比特。

参考资料:
https://ai . meta . com/blog/code-llama-large-language-model-coding/
魅族mx4好用吗
未经允许不得转载:科技让生活更美好 » Code Llama 70B霸榜3连发,练习5个月击败GPT-4!小扎LeCun亲自官宣上新







